基于YOLO的神经网络剪枝
基于YOLO的图像识别训练(英文手写体 + 生活中常见的事物(猫猫狗狗))
Abstract
本项目主要是针对于 YOLO v11的网络结构进行优化,来实现体积压缩和提高模型速度
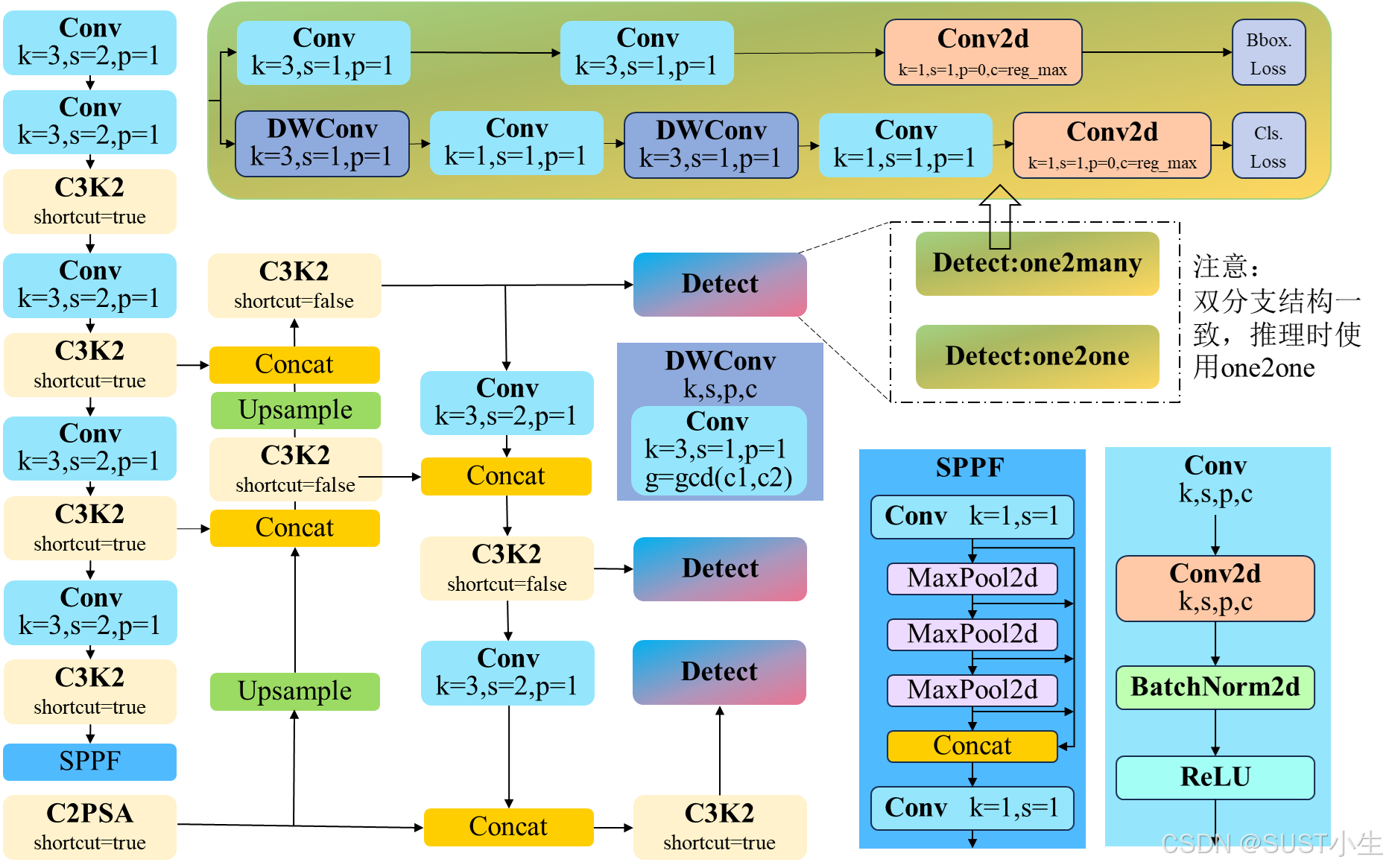
以下是 YOLO v11的模型结构图
数据清洗
由于在网络上没有相关手写体的YOLO数据集,所以我们要通过别人其他模型的数据集来自己构建一个与YOLO模型适配的数据集
首先我们需要关于手写体的基本数据集
首先这个数据集是缺少了YOLO所需要的坐标和类别等要求的,所以我们需要自己用PYTHON自动化来实现将其转换为YOLO所需要的格式

这个是满足YOLO的框的坐标格式
1 表示类别,后面表示中心坐标和长宽
1 | 1 0.500000 0.500000 1.000000 1.000000 |
以下附有代码
1 | import os |
进行 适配YOLO模型训练的数据集划分
训练集划分包括 模型训练部分,模型验证部分,如下图所示

1 | import os |
结果:
注意
划分数据集进行训练的时候需要保证每一个类别都应该有 训练的数据 和 推理的数据,如果存在不同类别需要在这个代码上进行细微调整(数据集划分的时候进行图片选择的时候,我们可以基于每一种类别的图片进行划分)

模型训练
进行完数据集划分,现在可以进行模型训练了。我是使用的 MAC,所以 device 是使用的 mps,如果是 windows的话,可以使用 GPU加速会快很多。
1 | from ultralytics import YOLO |
模型剪枝
参考相关文章 Learning Efficient Convolutional Networks Through Network Slimming
进行完模型训练后。
由于 我们想设计一个 便于在一些内存小的开发板上进行运行的模型,所以我们可以进行一些模型压缩,或者量化进行处理。这里我们采用的是模型剪枝操作。
我们采用的是L1正则化剪枝来对YOLO的网络结构进行剪枝,这里我们可以简单的介绍一下什么是 L1正则化剪枝流程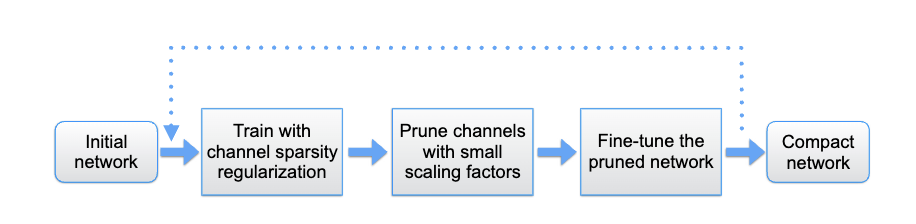
这是一个基本的流程,具体的操作都是可以基于 YOLO的网络结构训练代码进行修改的。接下来我们进行一个详细的介绍
这里的剪枝代码没有给出
通道权重压缩
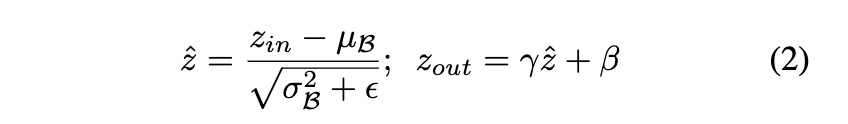
归一化就相当于把所有值通过比值关系,全部压缩到 0~1之间
这个是通道进行剪枝的计算公式来对L1层中的通道进行归一化处理,我们先进行 归一化处理,也可以称为约束训练,这是在训练过程中添加的部分
1 | # 对BN层进⾏L1正则化,约束训练时启⽤,正常训练时注释掉 |
进行完约束训练后,会生成一个训练的模型(.pt),然后我们再针对于这个 .pt 模型,进行模型剪枝,剪枝的操作相当于会删除网络结构中 权重小(影响因子小)的节点和边,从而实现稀少少量精度来实现压缩体积加快速度的效果。然后通过完剪枝的模型我们不能直接就进行图片推理,我们需要先进行回调训练,通过回调训练将模型的精度进行一下调整。就是将约束训练增加的代码给注释掉再进行训练就可以了。
这样剪枝的整个操作就实现完整了!
基于YOLO的神经网络剪枝